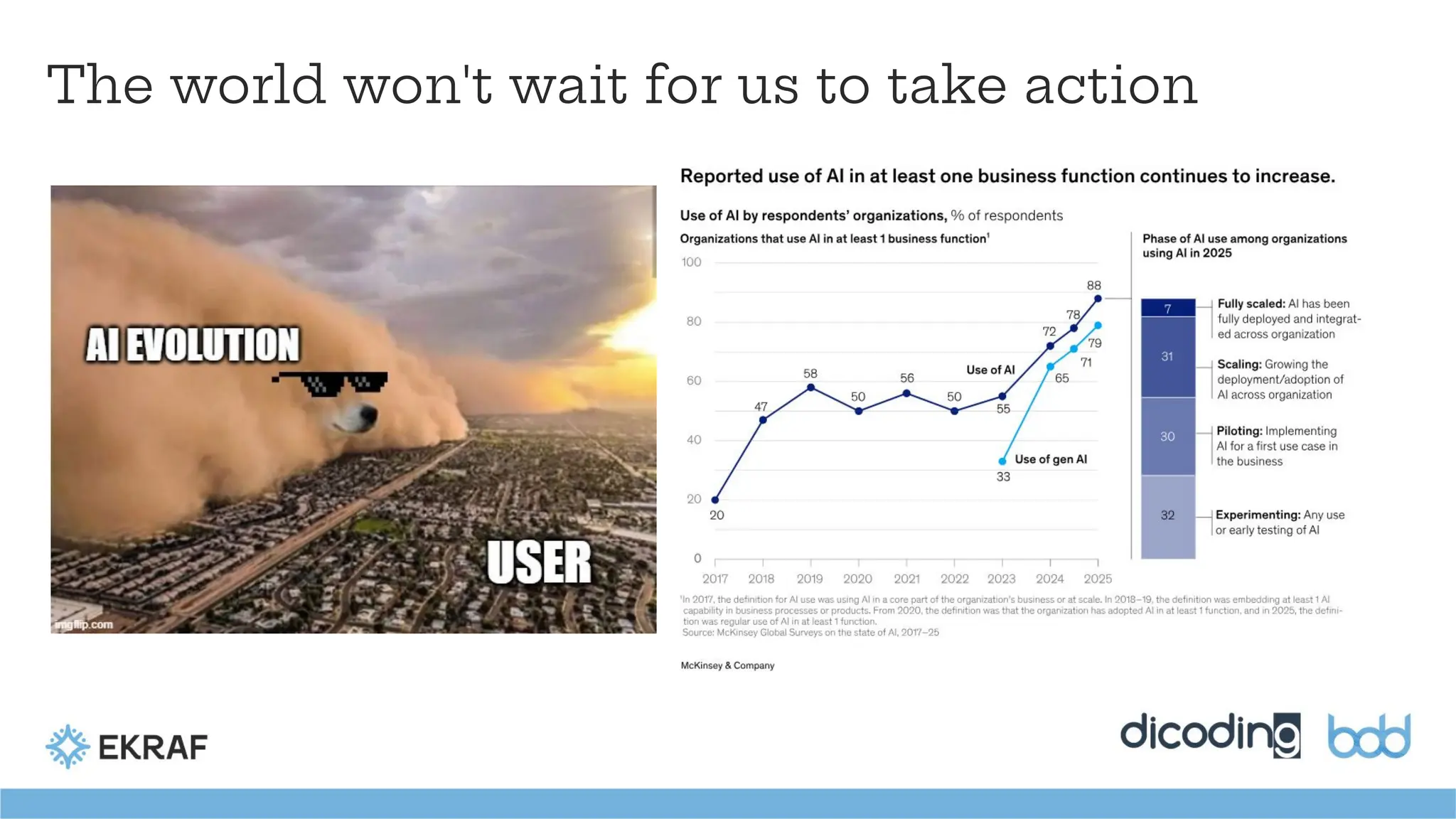
What is Love?
Whatdo users "love"?
Users crave a seamless experience.
They expect instant responses (low
latency), accurate, relevant, and reliable
answers (no hallucinations), and
interactions that feel personalized and
genuinely helpful.
What do companies "love"?
Companies operate based on metrics.
They demand operational efficiency, clear
and sustainable return on investment
(ROI), predictable and manageable costs,
sustainable competitive advantage, and,
most importantly, mitigation of legal and
reputational risks.
7.
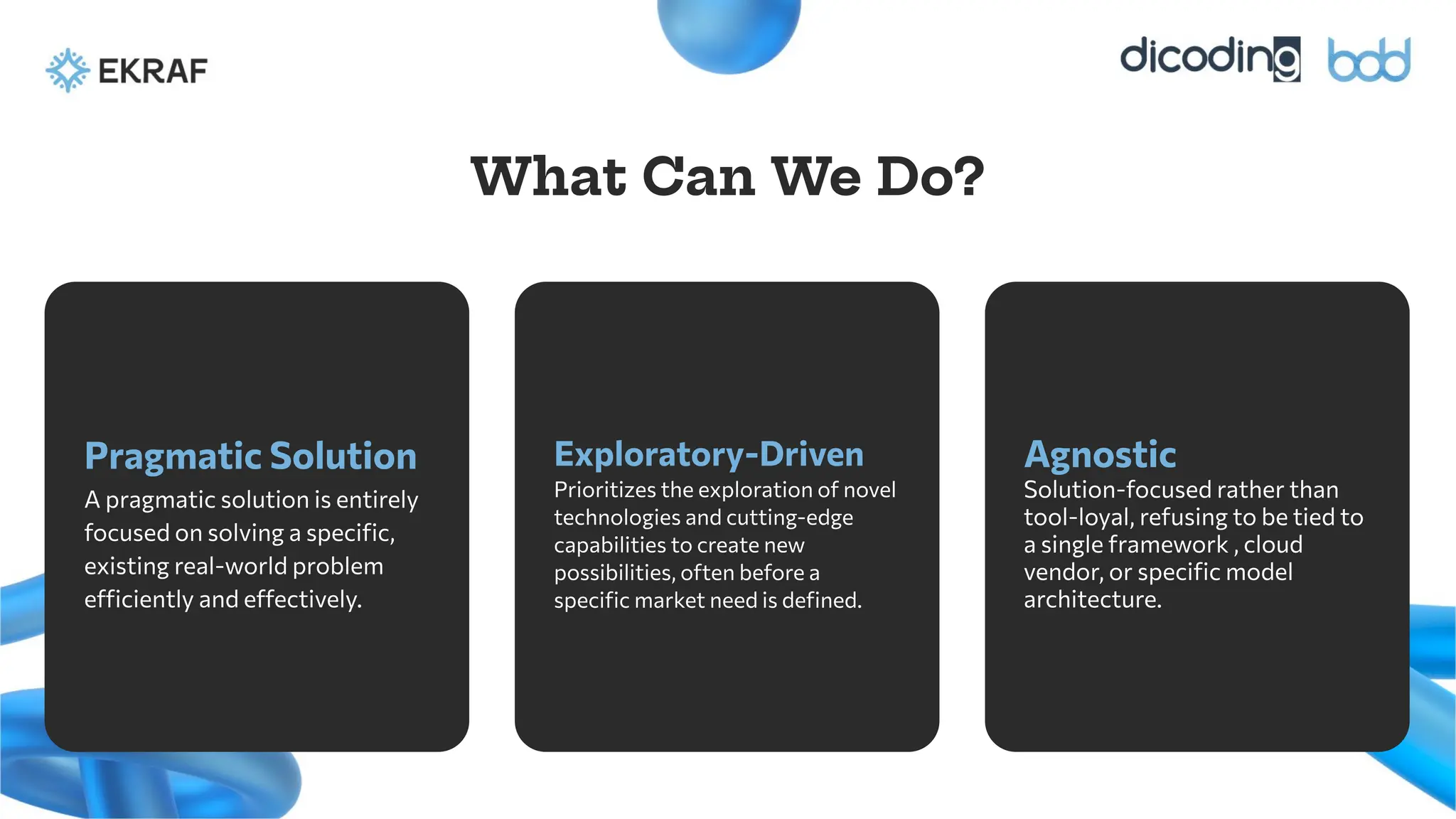
Pragmatic Solution
A pragmaticsolution is entirely
focused on solving a specific,
existing real-world problem
efficiently and effectively.
Exploratory-Driven
Prioritizes the exploration of novel
technologies and cutting-edge
capabilities to create new
possibilities, often before a
specific market need is defined.
What Can We Do?
Agnostic
Solution-focused rather than
tool-loyal, refusing to be tied to
a single framework , cloud
vendor, or specific model
architecture.
8.
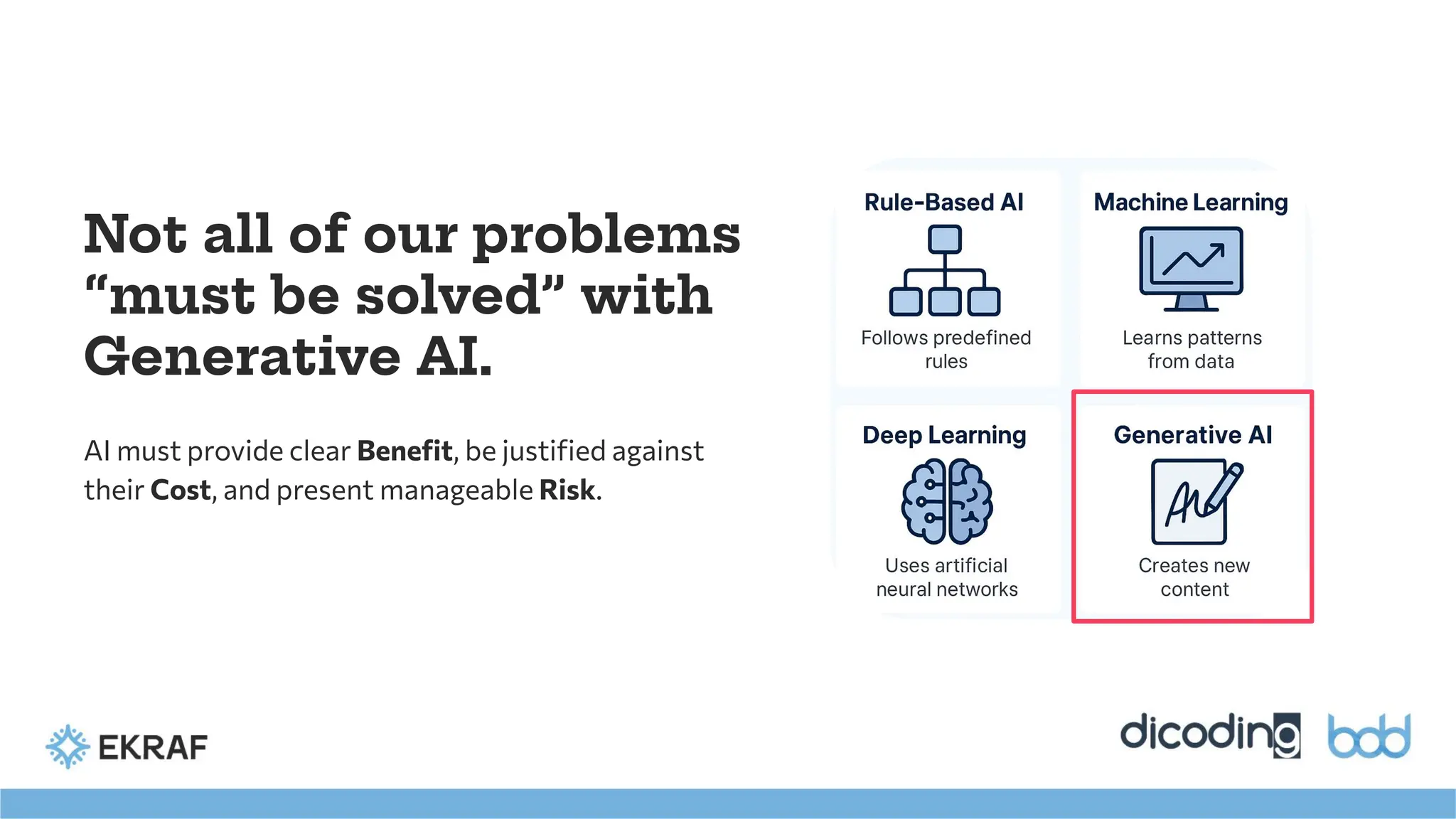
Not all ofour problems
“must be solved” with
Generative AI.
AI must provide clear Benefit, be justified against
their Cost, and present manageable Risk.
9.
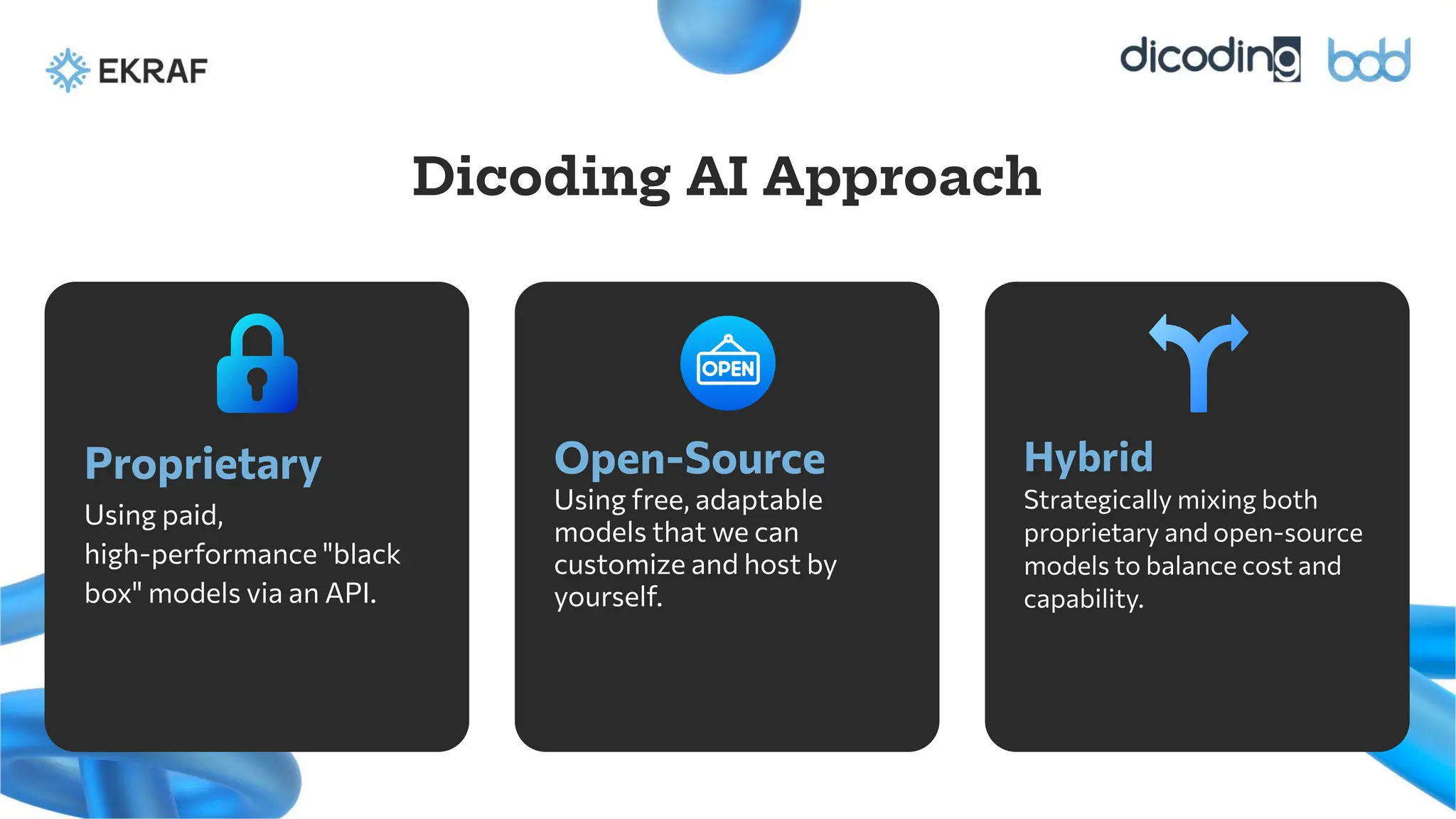
Dicoding AI Approach
Proprietary
Usingpaid,
high-performance "black
box" models via an API.
Open-Source
Using free, adaptable
models that we can
customize and host by
yourself.
Hybrid
Strategically mixing both
proprietary and open-source
models to balance cost and
capability.
10.
Implication
Operational
We achieved a74.98%
improvement in
operational efficiency.
Average Man
Hour
We freed up 80.9% of our
team's time for more
critical tasks.
Perusahaan X
Average productivity increase of 14%
(up to 34% for novice workers).
— Generative AI at Work (Working Paper 31161)
Perusahaan Y
Saved 12,000 hours of work in 18
months.
— YYY Case Study: Transforming HR with AI (AskHR)
As company movefrom tinkering to
deploying models in production, we’re face
three+one main concerns:
1. Cost: Significant for compute-intensive
AI applications.
2. Quality & Performance: Critical for AI
applications.
3. Security: Important for data residency
and preventing third-party models
from ingesting private data.
4. Tech Updates
Ofc, we are facing
several problems
13.
1. Operational Cost— API
So, one of the services that uses GPT-4.1
costs around $4.54
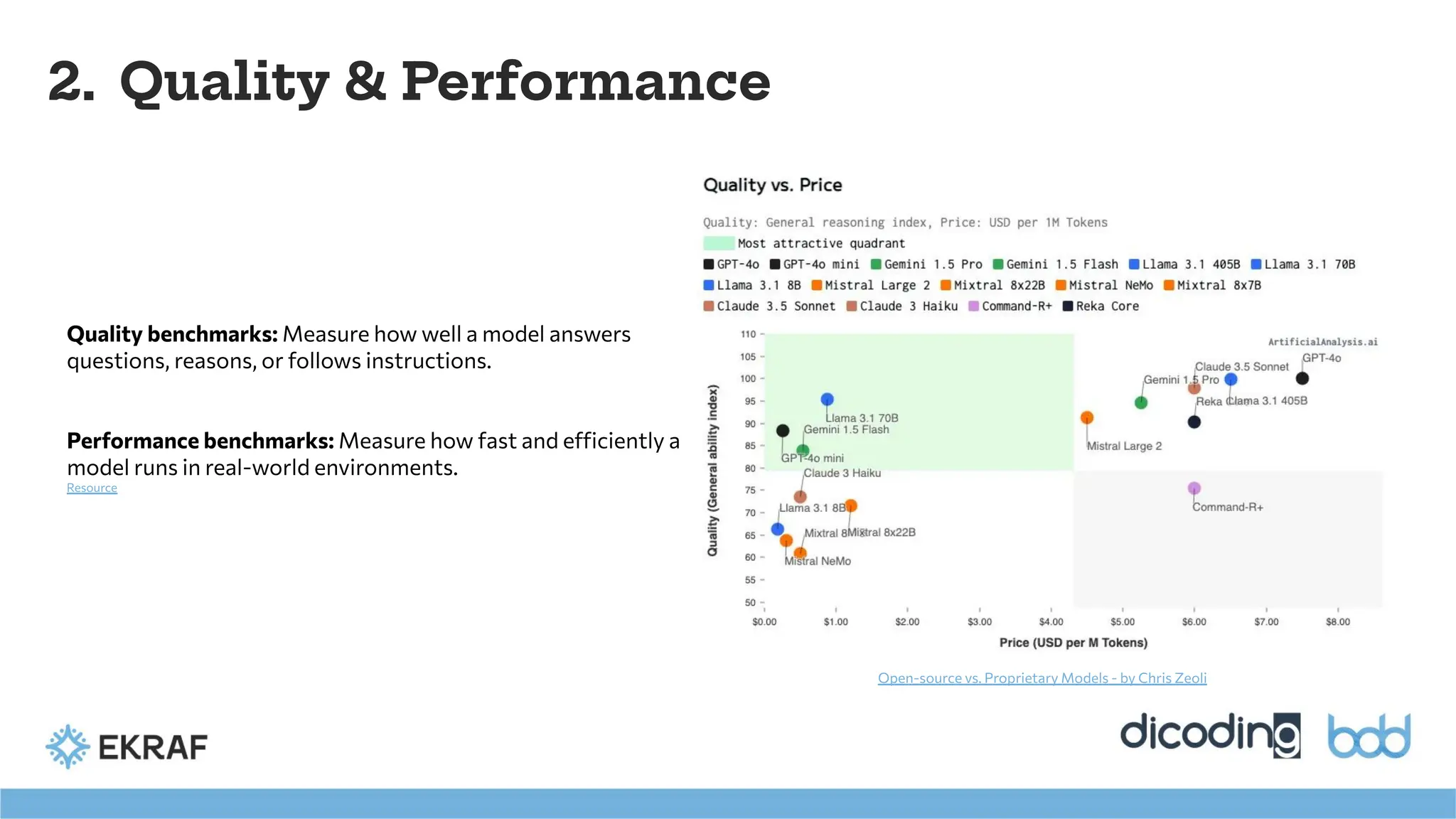
2. Quality &Performance
Open-source vs. Proprietary Models - by Chris Zeoli
Quality benchmarks: Measure how well a model answers
questions, reasons, or follows instructions.
Performance benchmarks: Measure how fast and efficiently a
model runs in real-world environments.
Resource
17.
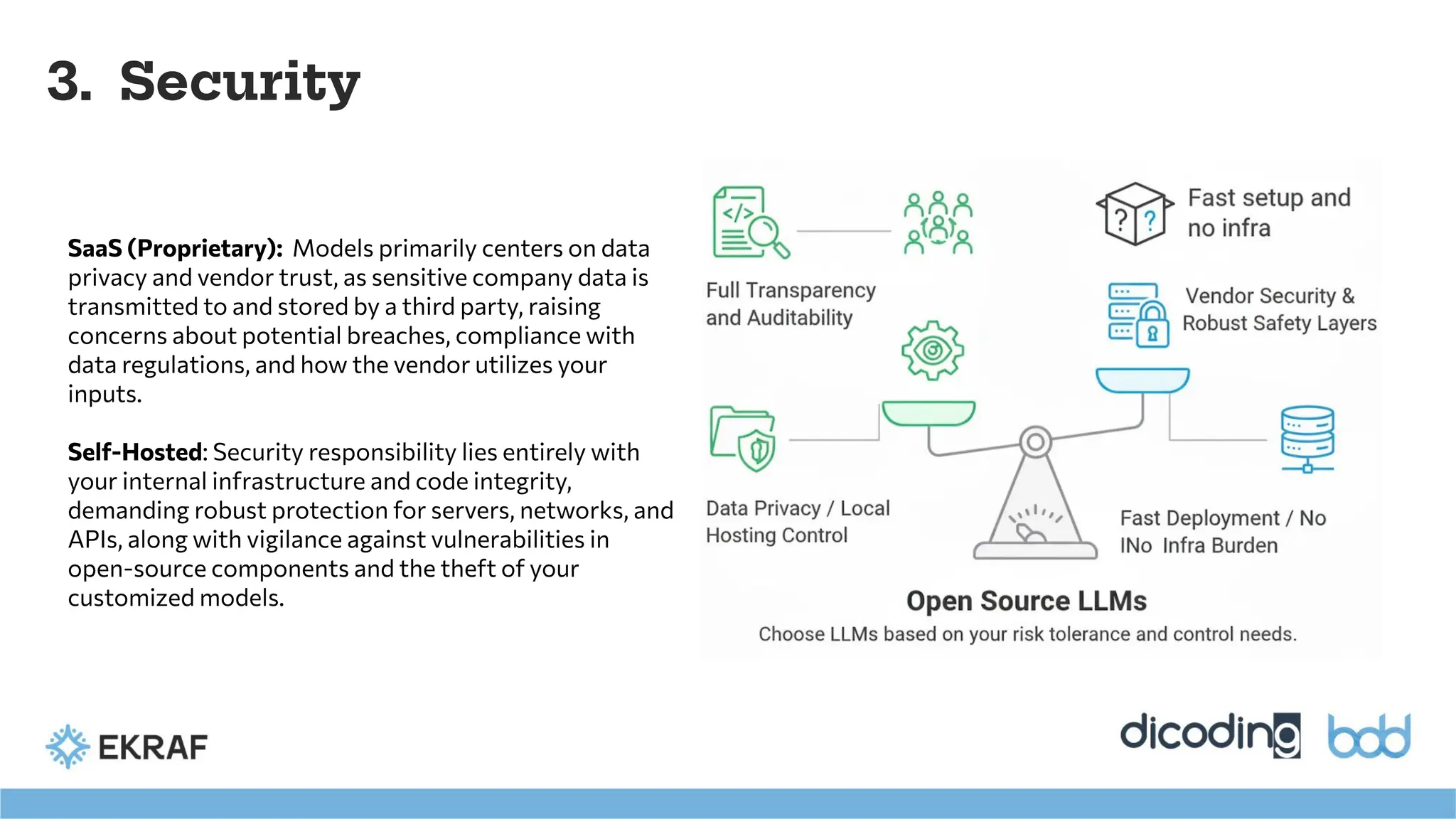
3. Security
SaaS (Proprietary):Models primarily centers on data
privacy and vendor trust, as sensitive company data is
transmitted to and stored by a third party, raising
concerns about potential breaches, compliance with
data regulations, and how the vendor utilizes your
inputs.
Self-Hosted: Security responsibility lies entirely with
your internal infrastructure and code integrity,
demanding robust protection for servers, networks, and
APIs, along with vigilance against vulnerabilities in
open-source components and the theft of your
customized models.
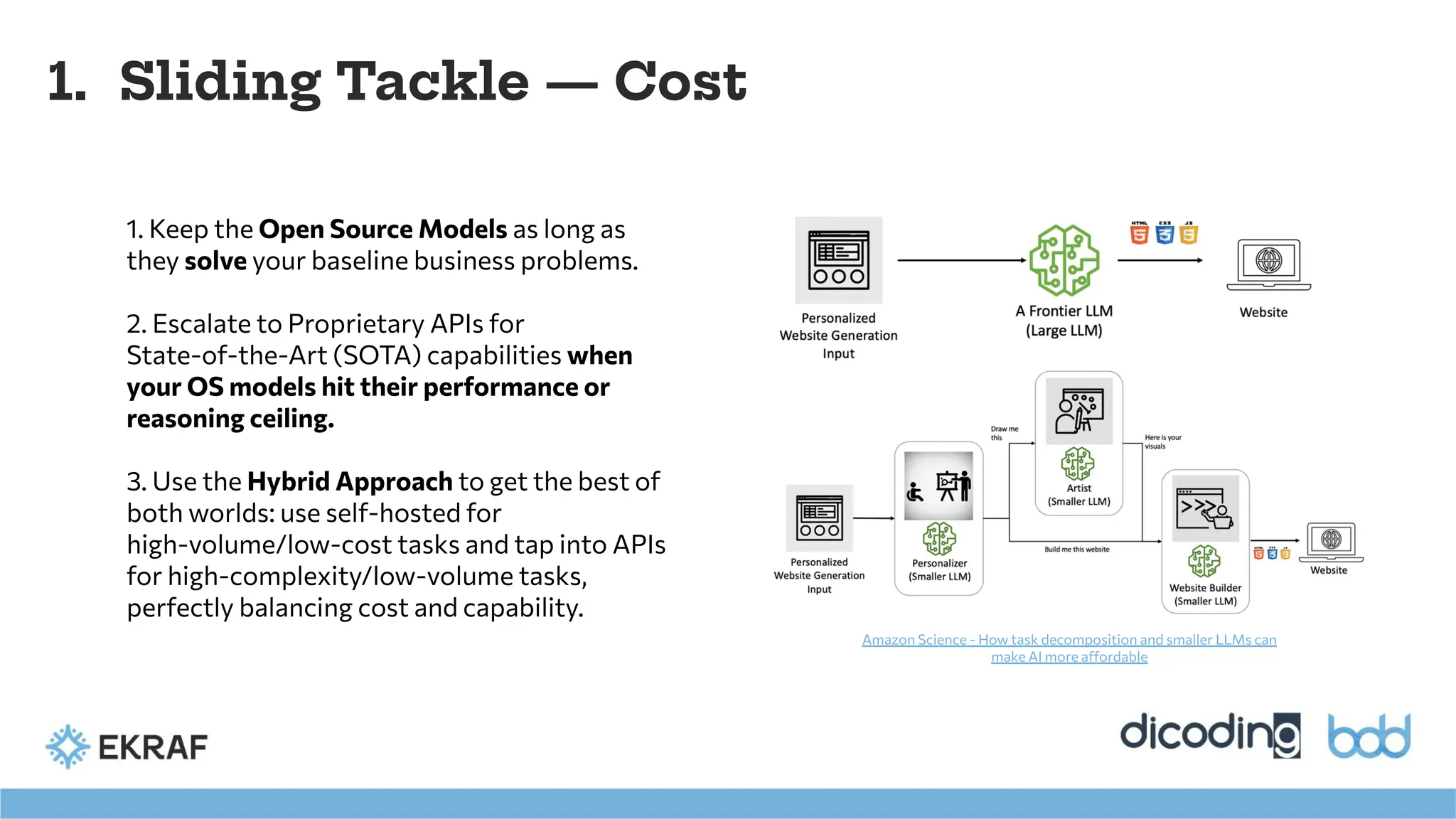
1. Sliding Tackle— Cost
SaaS vs On-Premise: Making Informed Software Decisions
The on-prem (self-hosted) approach
provides maximum control and data
security by keeping models in-house, but it
is expensive and difficult to scale for
"bursty" traffic.
Conversely, the SaaS (proprietary)
solution offers effortless scalability and
access to state-of-the-art models but
requires sacrificing data control and
trusting a third-party vendor.
21.
1. Sliding Tackle— Cost
1. Keep the Open Source Models as long as
they solve your baseline business problems.
2. Escalate to Proprietary APIs for
State-of-the-Art (SOTA) capabilities when
your OS models hit their performance or
reasoning ceiling.
3. Use the Hybrid Approach to get the best of
both worlds: use self-hosted for
high-volume/low-cost tasks and tap into APIs
for high-complexity/low-volume tasks,
perfectly balancing cost and capability.
Amazon Science - How task decomposition and smaller LLMs can
make AI more affordable
22.
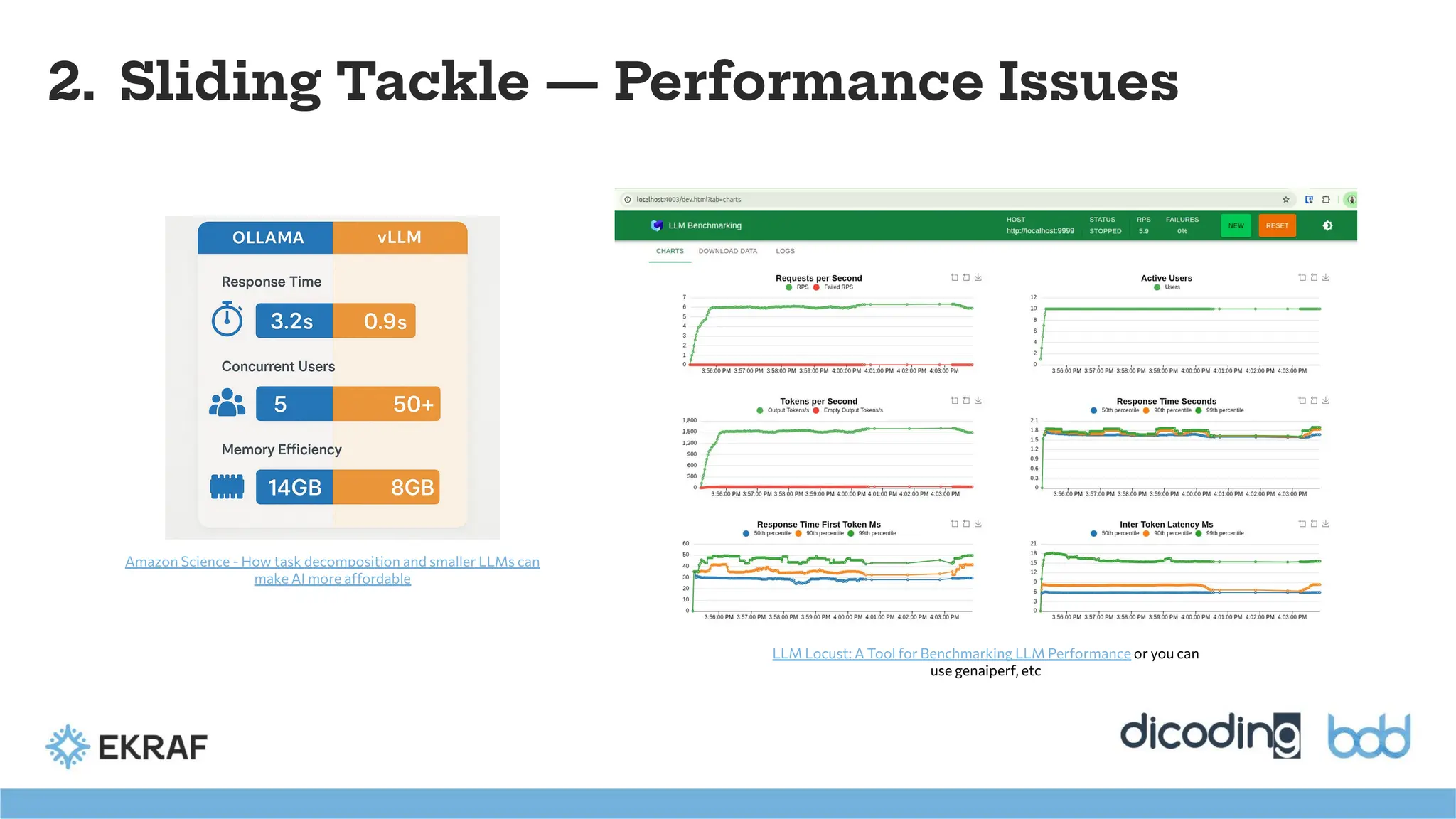
2. Sliding Tackle— Performance Issues
Pick the simplest tool that meets today’s needs, with headroom for
tomorrow. Start on a workstation (Ollama/LM Studio), move to a GPU
server (vLLM/SGLang), and standardize with Triton when you’re ready
to run many models.
1. Don't worry about SaaS as long as you
have internet access, money and they're not
down.
2. Self Host: Consider using smaller models.
3. The hybrid approach bridges this gap by
using secure on-prem systems for sensitive,
baseline workloads while "overflowing" to
the cloud to manage peak demand,
strategically balancing cost, control, and
elasticity.
23.
2. Sliding Tackle— Performance Issues
Amazon Science - How task decomposition and smaller LLMs can
make AI more affordable
LLM Locust: A Tool for Benchmarking LLM Performance or you can
use genaiperf, etc
24.
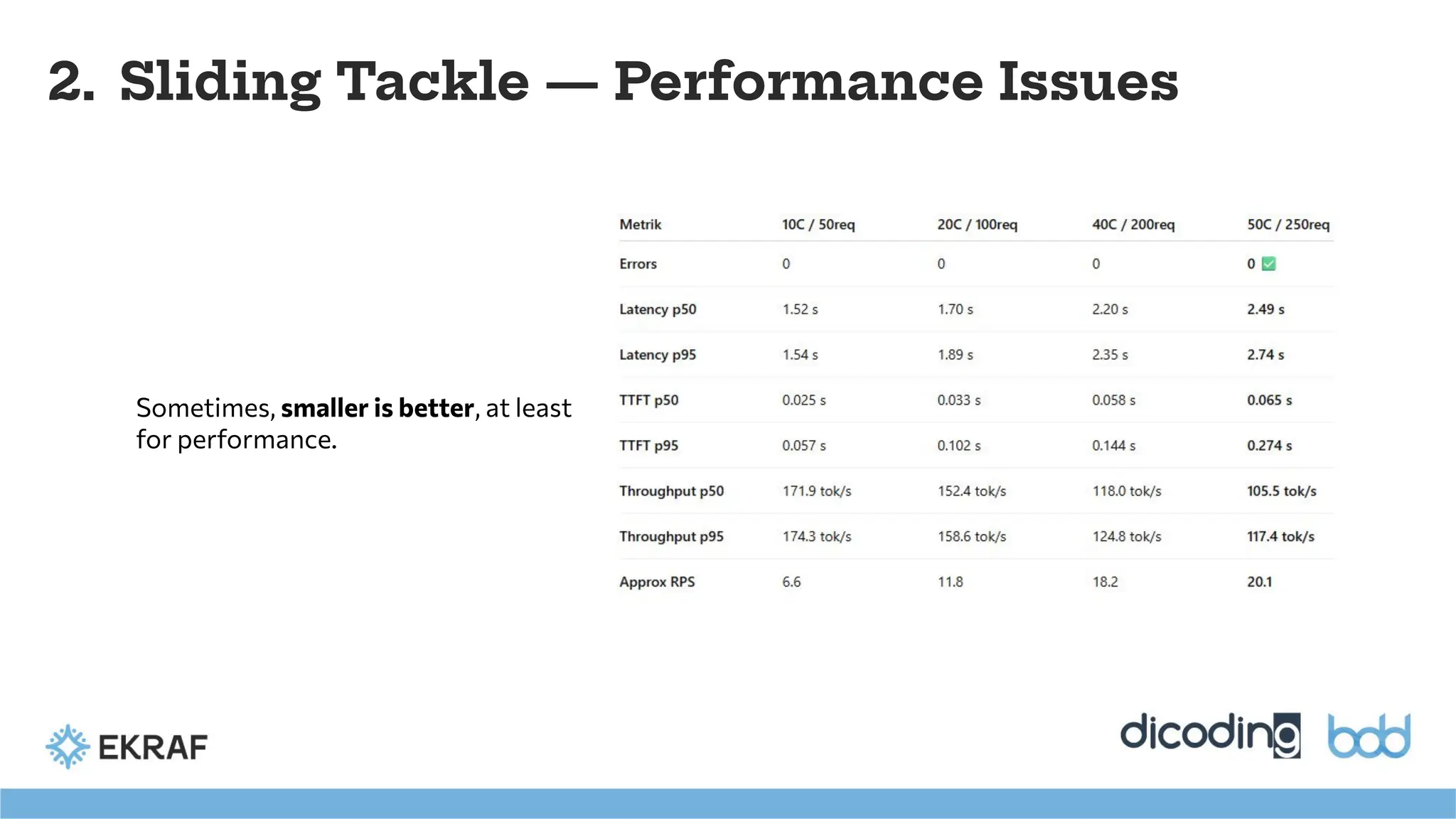
2. Sliding Tackle— Performance Issues
Sometimes, smaller is better, at least
for performance.
25.
2. Sliding Tackle— Quality Issues
A language
model is simply a computational
system that can predict the next word
from previous words.
— Speech and Language Processing 3rd Edition, Large Language
Models, Dan Jurafsky and James H. Martin.
Accuracy does not scale linearly with size; SLMs often match LLMs on
structured or narrow tasks, while LLMs consistently outperform on
complex reasoning.
Quantization Pruning
Distillation LoRA
Building SLM from Scratch
26.
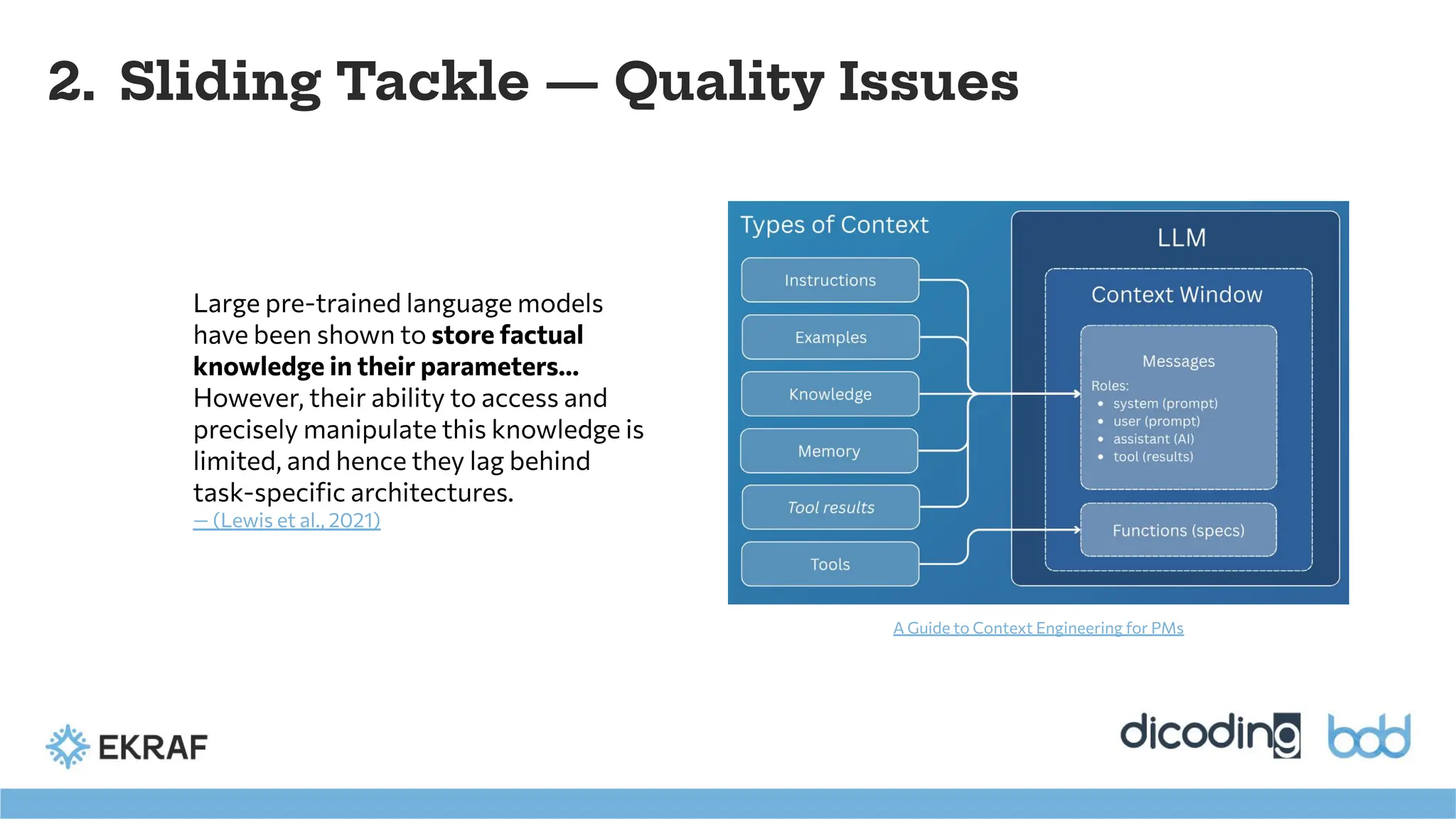
2. Sliding Tackle— Quality Issues
A Guide to Context Engineering for PMs
Large pre-trained language models
have been shown to store factual
knowledge in their parameters...
However, their ability to access and
precisely manipulate this knowledge is
limited, and hence they lag behind
task-specific architectures.
— (Lewis et al., 2021)
27.
2. Sliding Tackle— Quality Issues
Faithfulness: Does the model's answer truly come
from the given context (to prevent hallucinations)?
Answer Relevance: Does the model's answer truly
answer the user's question?
Coherence: Are the sentences coherent and logical?
Safety/Toxicity: Is there any harmful, biased, or
policy-violating output?
Human Evaluator
"Deploying a systemis not the end. It’s the
beginning. Once a system is deployed, it
interacts with the real world... and the real
world changes."
— Chip Huyen, Designing Machine Learning Systems: An Iterative
Process for Production-Ready Applications
We Never Finish the Projects — Not yet
32.
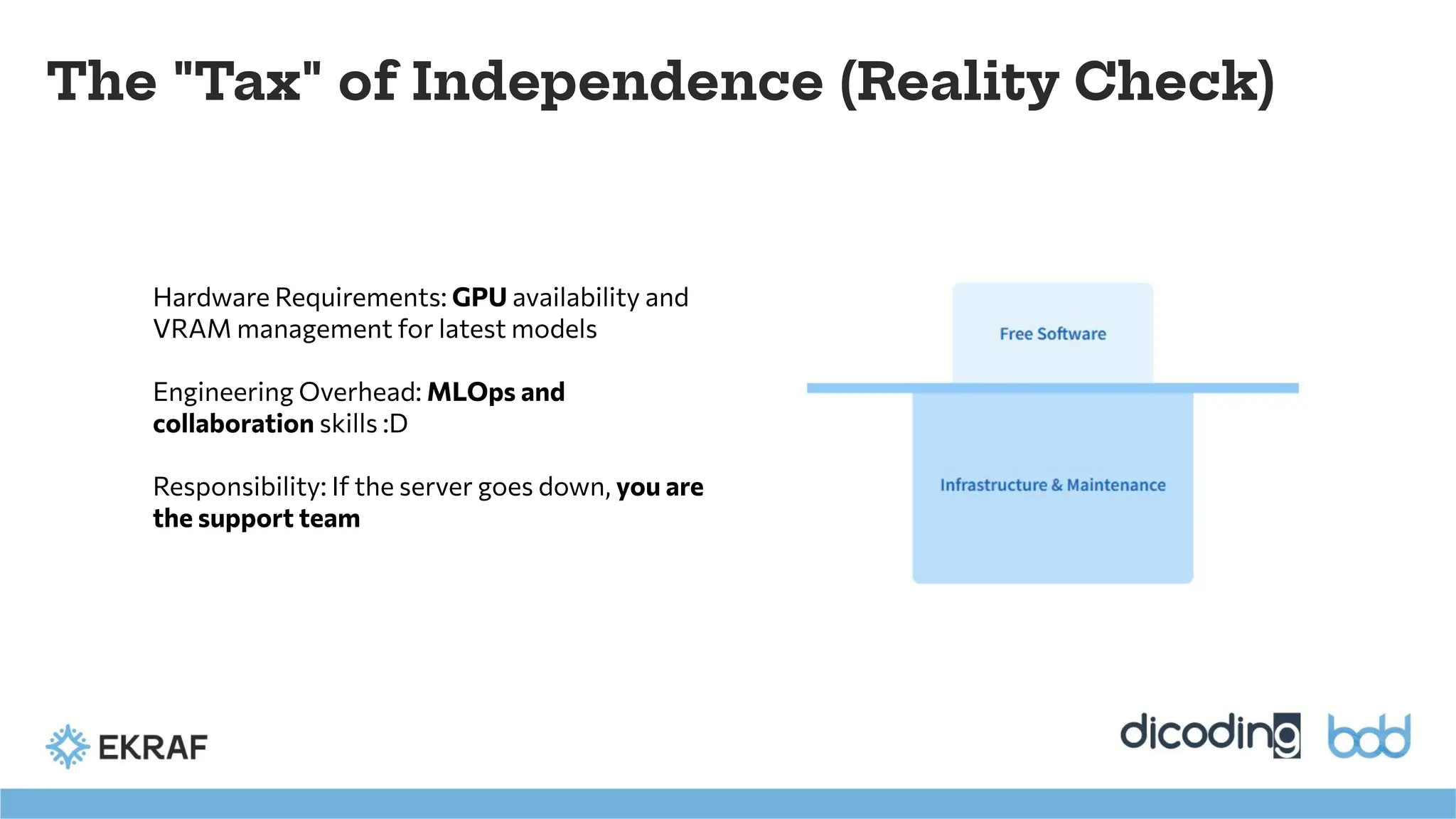
The "Tax" ofIndependence (Reality Check)
Hardware Requirements: GPU availability and
VRAM management for latest models
Engineering Overhead: MLOps and
collaboration skills :D
Responsibility: If the server goes down, you are
the support team
33.
A Survival Guidefor Developer Myself
Abstraction Layers: Never hardcode a model. Use
agnostic interfaces (e.g., AI SDK, LiteLLM) to swap
backends instantly.
Evaluation Driven Development (EDD): Trust your test
suite, not the hype. Run 'evals' to verify if a new model
actually improves your specific use case.
Dynamic Routing: Don't use a cannon to kill a mosquito.
Route simple tasks to fast/local models and complex
logic to SOTA models.
"The goal isn't to pick the best model forever, but to build a system that can adapt to the
best model of the month."























![Conviction LP Letter - Dec 2023 [Redacted]](https://cdn.slidesharecdn.com/ss_thumbnails/convictionlpletter-dec2023sentredacted-250215033237-61bacefc-thumbnail.jpg?width=640&height=640&fit=bounds)






![Conviction LP Letter - May 2024 [Redacted]](https://cdn.slidesharecdn.com/ss_thumbnails/convictionlpletter-may2024sentredacted-250215033505-a84e3cae-thumbnail.jpg?width=640&height=640&fit=bounds)

![Conviction LP Letter - Jan 2025 [Redacted]](https://cdn.slidesharecdn.com/ss_thumbnails/convictionlpletterjan2025sentredacted-250215033551-3d3d9795-thumbnail.jpg?width=640&height=640&fit=bounds)















![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Beyond 'It Works': A Case Study on Real-...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-beyonditworksacasestudyonreal-worldairisk-251124030839-684bec68-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building a Data Architecture for Sub-Sec...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingadataarchitectureforsub-secondanalysis-251124030841-2110604d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)











