MODULE 4
Shared-memory programmingwith OpenMP –
● OpenMP pragmas and directives
● trapezoidal rule
● Scope of variables
● reduction clause
● loop carried dependency
● scheduling
● producers and consumers
● Caches, cache coherence and false sharing in OpenMP
● tasking
● thread safety
2
Prepared by: Prof Bibi Annie Oommen,
Dept of CSE, CMR Institute of Technology
3.
Introduction
● OpenMP isan API for shared-memory MIMD
programming.
● The “MP” in OpenMP stands for “multiprocessing,” a term
that is synonymous with shared-memory MIMD
computing.
Prepared by: Prof Bibi Annie Oommen,
Dept of CSE, CMR Institute of Technology
4.
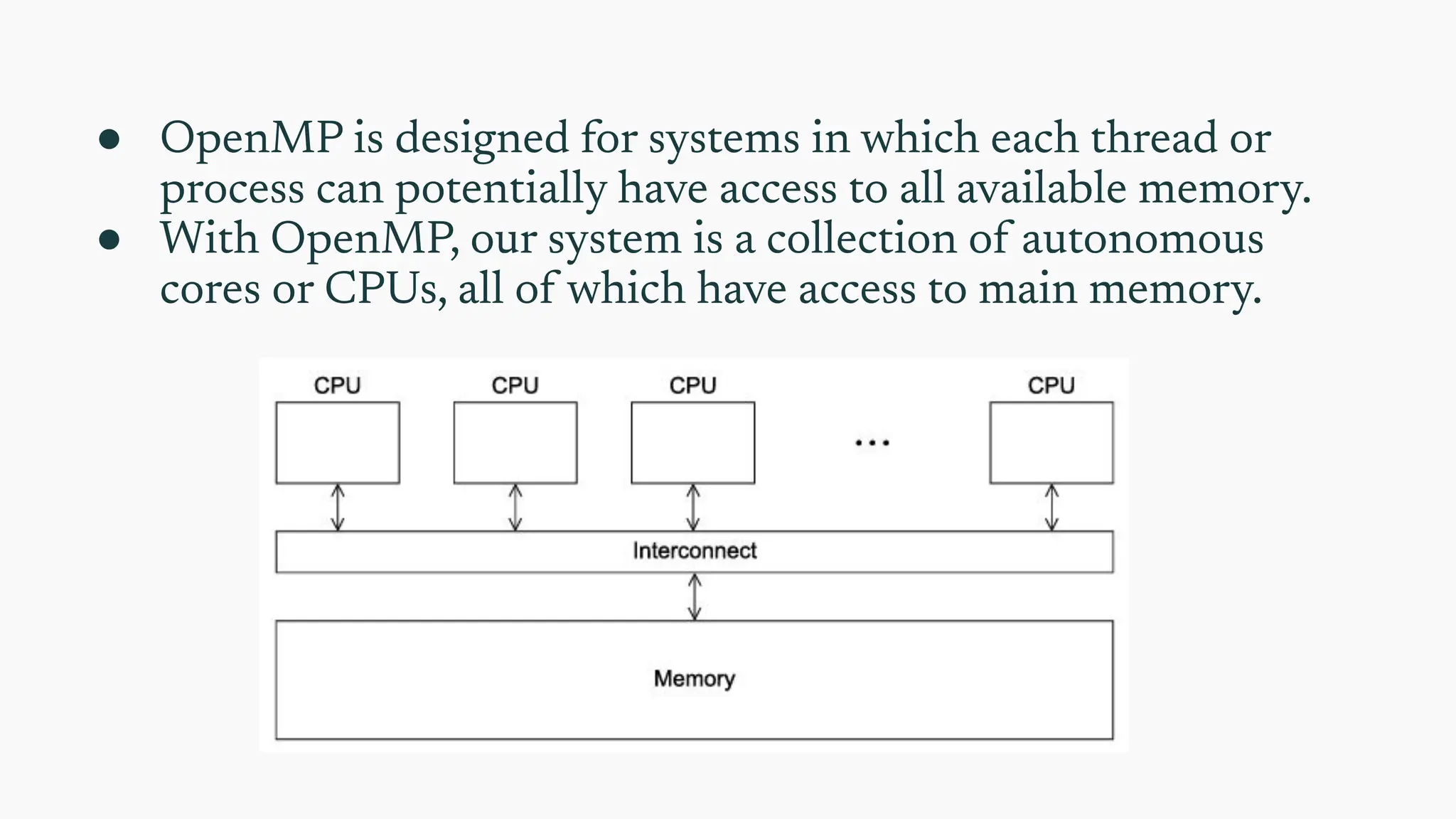
● OpenMP isdesigned for systems in which each thread or
process can potentially have access to all available memory.
● With OpenMP, our system is a collection of autonomous
cores or CPUs, all of which have access to main memory.
5.
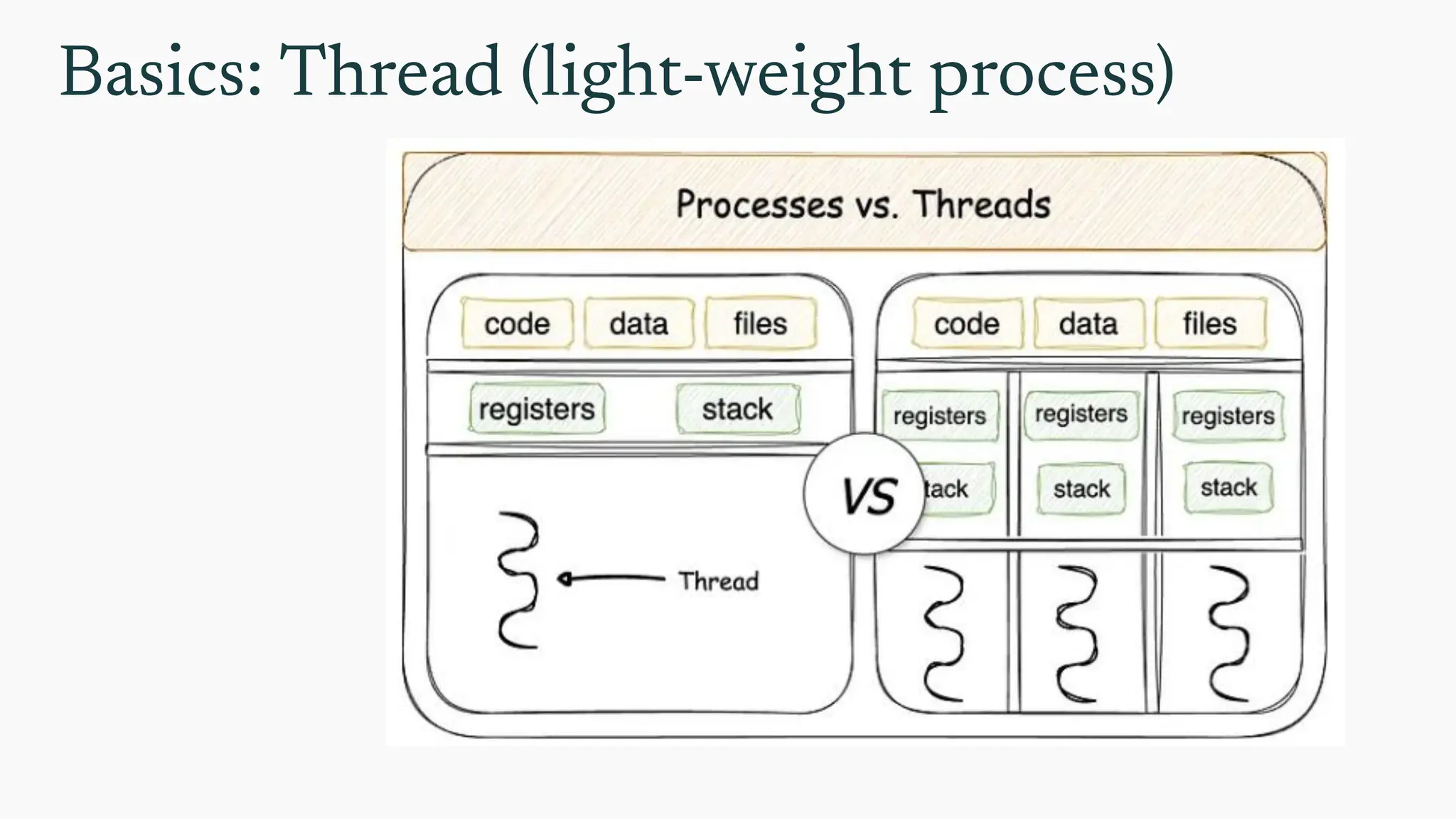
Basics: The Process
Processmemory is divided into four sections :
● The text section comprises the compiled program
code, read in from non-volatile storage when the
program is launched.
● The data section stores global and static variables,
allocated and initialized prior to executing main.
● The heap is used for dynamic memory allocation,
and is managed via calls to new, delete, malloc,
free, etc.
● The stack is used for local variables. Space on the
stack is reserved for local variables when they are
declared ( at function entrance or elsewhere,
depending on the language ), and the space is
freed up when the variables go out of scope. Note
that the stack is also used for function return
values
A process in memory
6.
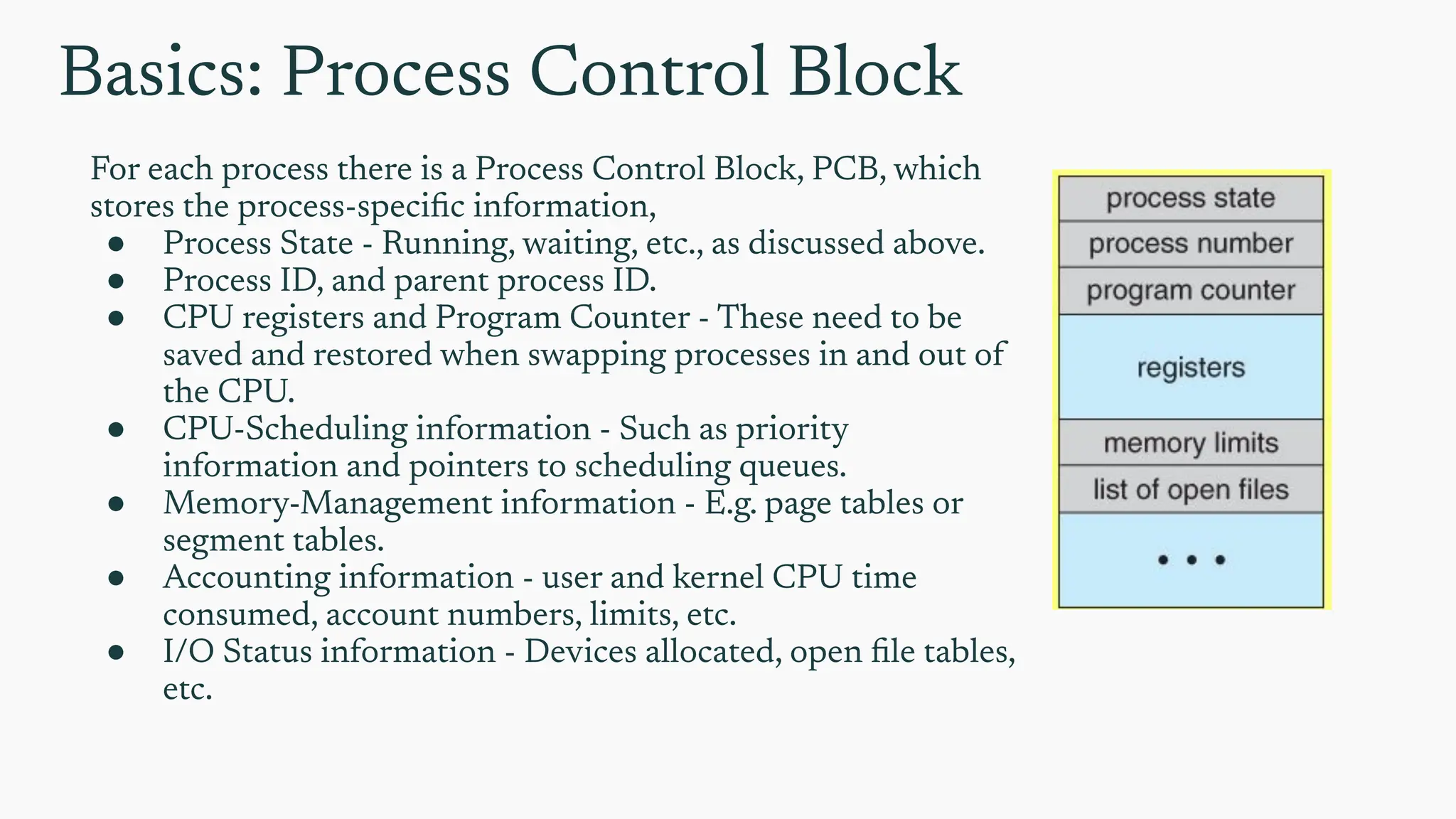
Basics: Process ControlBlock
For each process there is a Process Control Block, PCB, which
stores the process-specific information,
● Process State - Running, waiting, etc., as discussed above.
● Process ID, and parent process ID.
● CPU registers and Program Counter - These need to be
saved and restored when swapping processes in and out of
the CPU.
● CPU-Scheduling information - Such as priority
information and pointers to scheduling queues.
● Memory-Management information - E.g. page tables or
segment tables.
● Accounting information - user and kernel CPU time
consumed, account numbers, limits, etc.
● I/O Status information - Devices allocated, open file tables,
etc.
OpenMP:
directives -based sharedmemory API
C and C++ use special preprocessor instructions (pragmas)
● Pragmas in C and C++ start with #pragma
● Pragmas (like all preprocessor directives) are one line in
length, so if a pragma won’t fit on a single line,the newline
needs to be“escaped”—that is, preceded by a backslash
What actually happenswhen the program gets
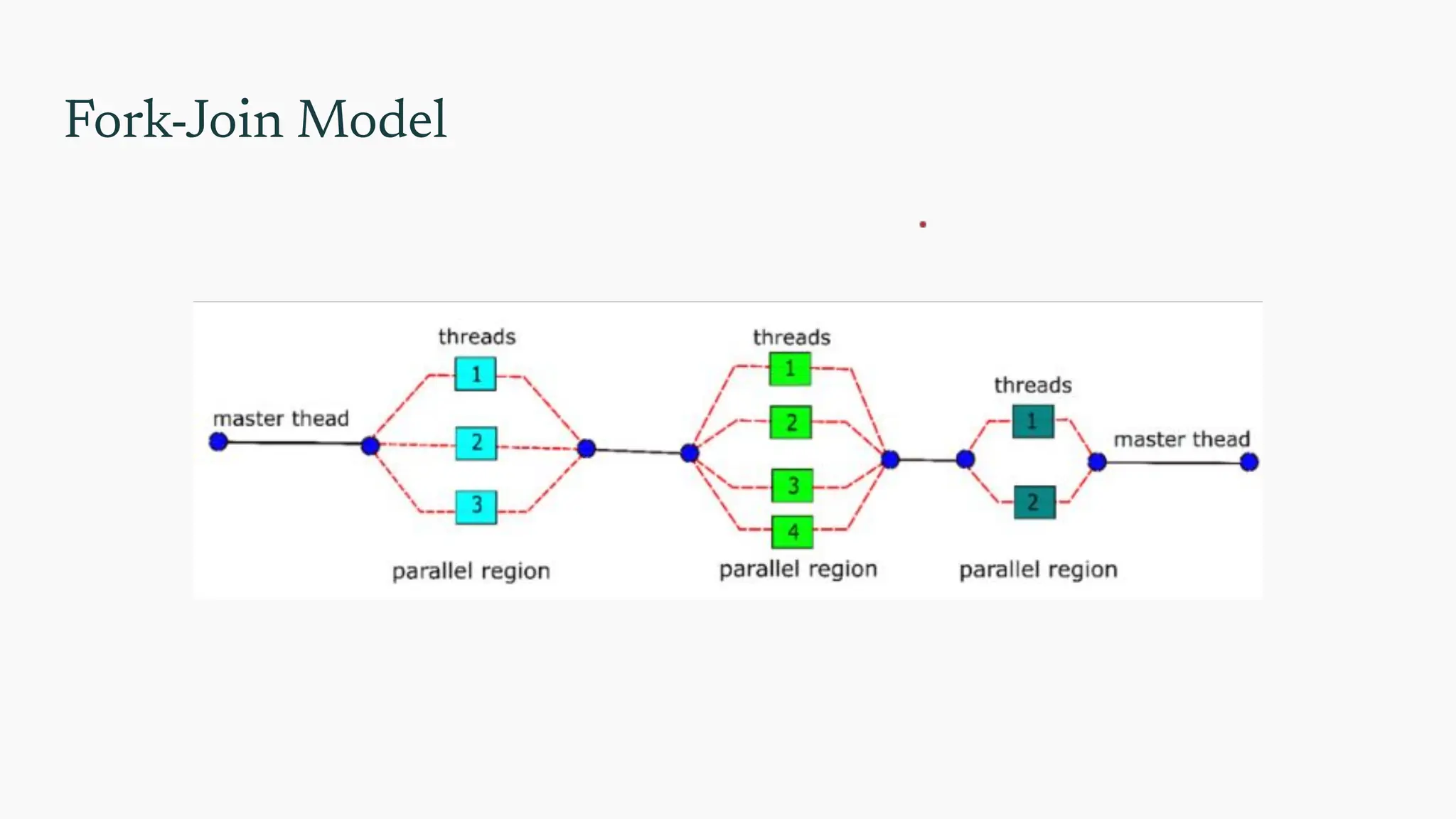
to the parallel directive?
● Prior to the parallel directive, the program is using a single thread, the
process started when the program started execution.
● When the program reaches the parallel directive, the original thread continues
executing and thread_count − 1 additional threads are started.
● When the block of code is completed, there’s an implicit barrier. This means
that a thread that has completed the block of code will wait for all the other
threads in the team to complete the block.
● When all the threads have completed the block, the child threads will
terminate and the parent thread will continue executing the code that follows
the block.
OpenMP thread terminology
●Team: the collection of threads executing the parallel block—the original
thread and the new threads
● master: the first thread of execution, or thread 0.
● parent: thread that encountered a parallel directive and started a team of
threads. In many cases, the parent is also the master thread.
● child: each thread started by the parent is considered a child thread
15.
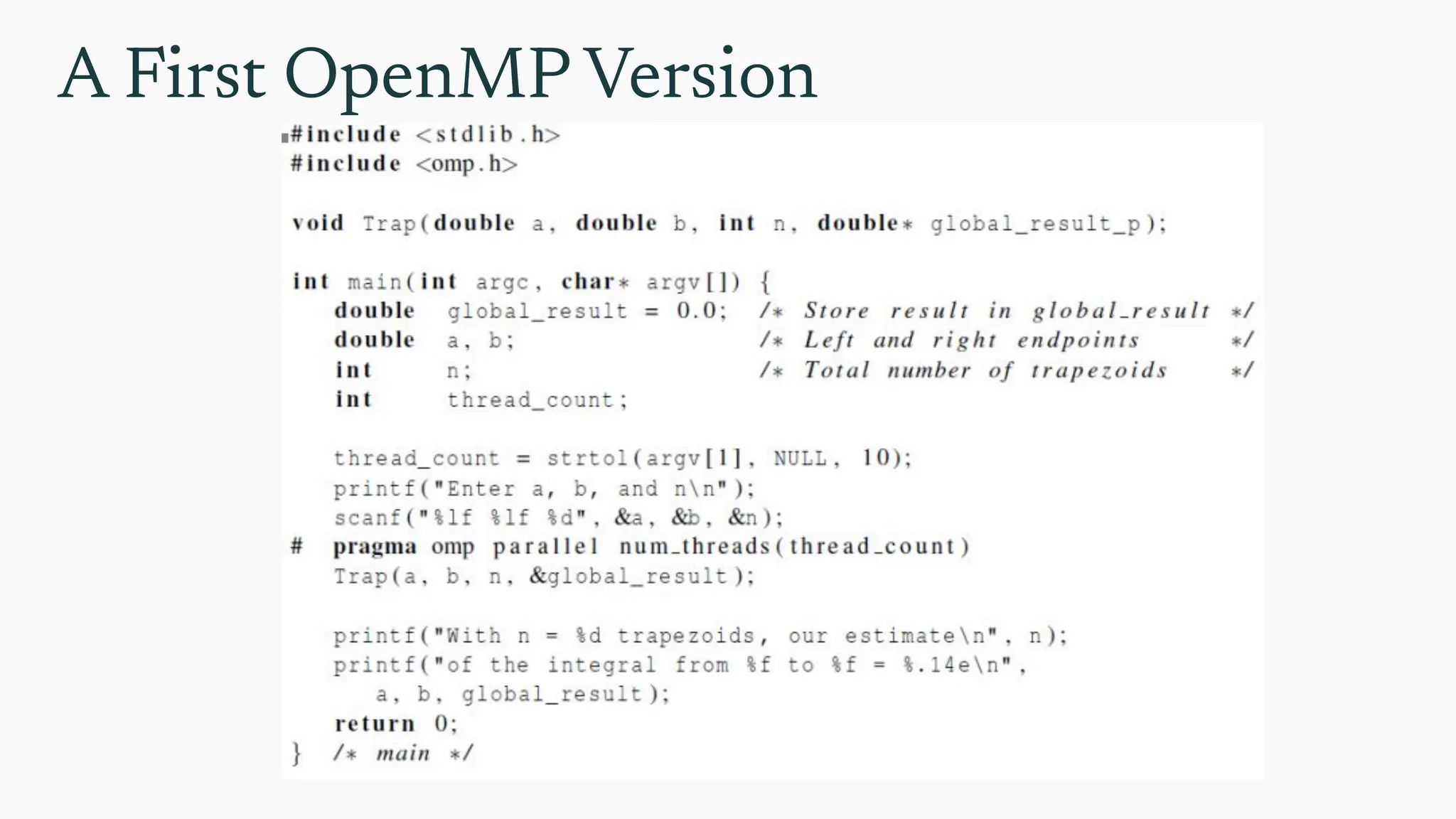
Hello World inOpenMP #include <omp.h>
Brings in OpenMP functions like
omp_get_thread_num()
#pragma omp parallel
Tells the compiler to run the
following block in parallel
omp_get_thread_num()
Returns the thread ID (0 to n-1) of
the calling thread
{ ... }
The parallel region executed
by multiple threads
omp_set_num_threads()
how many threads are used in
a parallel region
16.
Note:
● Calling omp_get_num_threads()outside a parallel region returns 1.
● If num_threads(n) is used in a pragma, it overrides
omp_set_num_threads(n) for that region.
17.
Test Code in
OnlineGDB
#include <stdio.h>
#include <omp.h>
int main()
{
int n = omp_get_num_threads();
printf("n thread id outside pragma %d", omp_get_thread_num());
printf("n Outside Pragma: number of threads %d", n);
omp_set_num_threads(6);
printf("n number of threads after set %d",
omp_get_num_threads());
#pragma omp parallel
{
printf("n Inside pragma: number of threads after set %d",
omp_get_num_threads());
printf("n Hello World OMP from thread %d",
omp_get_thread_num());
}
return 0;
}
18.
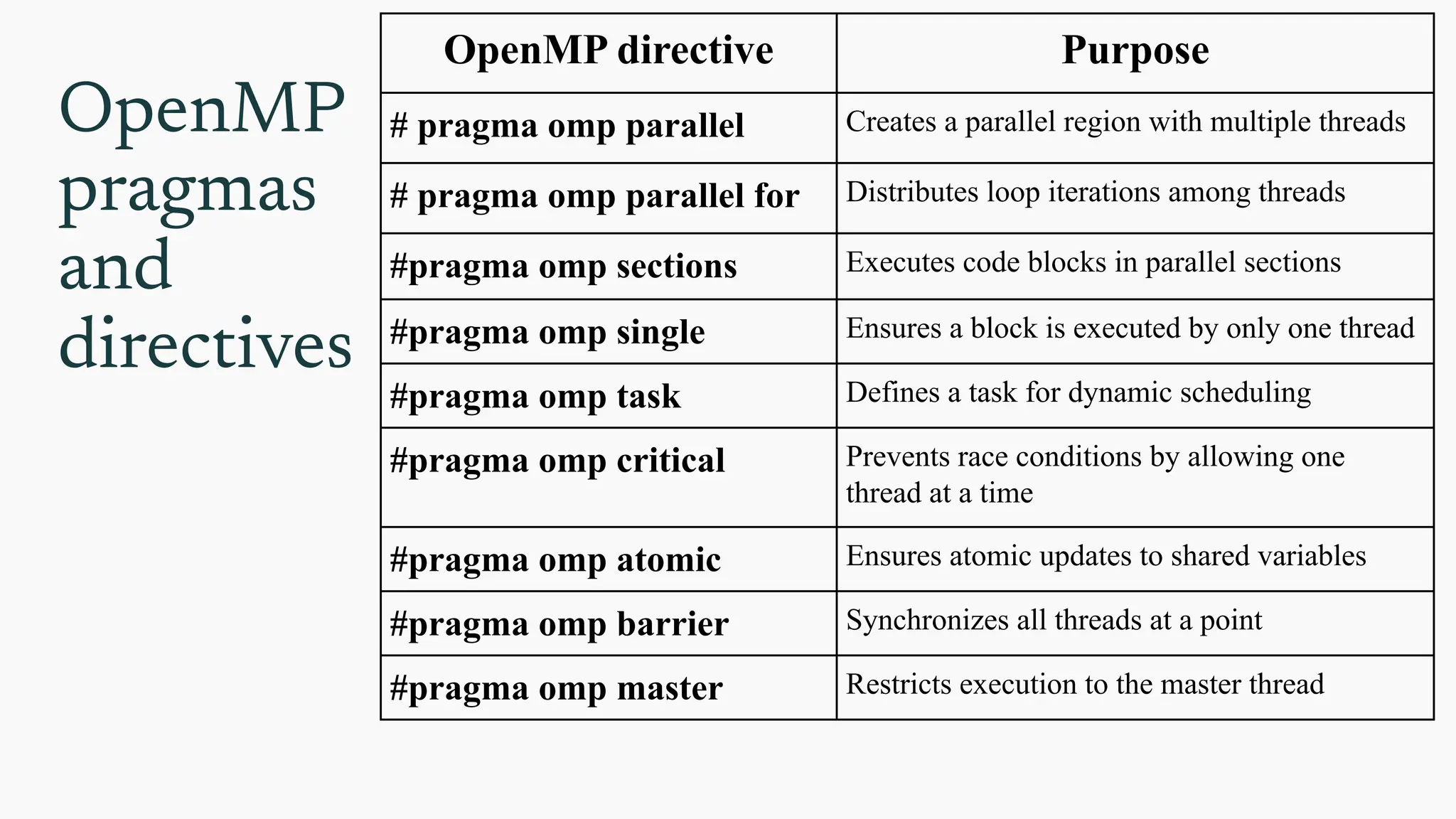
OpenMP
pragmas
and
directives
OpenMP directive Purpose
#pragma omp parallel Creates a parallel region with multiple threads
# pragma omp parallel for Distributes loop iterations among threads
#pragma omp sections Executes code blocks in parallel sections
#pragma omp single Ensures a block is executed by only one thread
#pragma omp task Defines a task for dynamic scheduling
#pragma omp critical Prevents race conditions by allowing one
thread at a time
#pragma omp atomic Ensures atomic updates to shared variables
#pragma omp barrier Synchronizes all threads at a point
#pragma omp master Restricts execution to the master thread
19.
Directive Purpose TypicalUse Case
#pragma omp parallel Create a team of threads General parallel code
blocks
#pragma omp for Divide loop iterations
among threads
Must be inside a
parallel region
#pragma omp parallel
for
Combines both: creates
threads and splits loop
Parallelizing loops
directly
Equivalent Forms
20.
Common Clauses with#pragma omp parallel
Clause Purpose
num_threads(n) Specifies the number of threads to use in
the parallel region
private(varlist) Each thread gets its own uninitialized copy
of the listed variables
shared(varlist) Variables are shared among all threads
firstprivate(varlist) Each thread gets its own copy, initialized
from the master thread
reduction(op:varlist) Combines thread-local results using an
operator (e.g. +, *)
two types oftasks:
a) computation of the areas of individual trapezoids, and
b) adding the areas of trapezoids.
There is no communication among the tasks in the first collection,
but each task in the first collection communicates with task b.
Scope of variables
●In OpenMP, the scope of a variable refers to the set of threads that can
access the variable in a parallel block.
● A variable that can be accessed by all the threads in the team has shared
scope, while a variable that can only be accessed by a single thread has
private scope.
● Variables that have been declared before a parallel directive have shared
scope among the threads in the team, while variables declared in the
block (e.g., local variables in functions) have private scope.
28.
Typically, any variablethat was defined before the OpenMP directive has
shared scope within the construct. That is, all the threads have access to
it. There are a exceptions to this.
● The first is that the loop variable in a for or parallel for construct is private,
that is, each thread has its own copy of the variable.
● The second exception is that variables used in a task construct have
private scope.
Variables that are defined within an OpenMP construct have private
scope, since they will be allocated from the executing thread’s stack.
29.
It’s a goodidea to explicitly assign the scope of variables.
This can be done by modifying a parallel or parallel for directive with the
scoping clause: default ( none )
This tells the system that the scope of every variable that’s used in the
OpenMP construct must be explicitly specified. This can be done with
private or shared clauses.
30.
Reduction
● A reductionoperator is an associative binary operation (such as addition
or multiplication)
● reduction is a computation that repeatedly applies the same reduction
operator to a sequence of operands to get a single result.
● all of the intermediate results of the operation should be stored in the same
variable: the reduction variable.
31.
#include <omp.h>
#include <stdio.h>
intmain() {
int A[10];
for (int i = 0; i < 10; i++) A[i] = i;
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10; i++) {
sum += A[i]; // Race condition!
}
printf("Sum = %dn", sum);
return 0;
}
Sum the elements of an array in parallel- without reduction clause
All threads try to update
sum simultaneously.
This causes a race
condition — unpredictable
results
.
Not thread-safe unless
you use atomic, critical, or
reduction.
32.
#include <omp.h>
#include <stdio.h>
intmain() {
int A[10];
for (int i = 0; i < 10; i++) A[i] = i;
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 10; i++) {
sum += A[i];
}
printf("Sum = %dn", sum);
return 0;
}
Sum the elements of an array in parallel- with reduction clause
Each thread gets a private
copy of sum.
After the loop, OpenMP
automatically combines all
partial sums.
Thread-safe, no race
conditions.
33.
Incrementing a sharedcounter in a parallel loop: Without Protection (Race
Condition)
int counter = 0;
#pragma omp parallel for
for (int i = 0; i < 1000; i++) {
counter++; // Unsafe}
Threads may read and write counter
at the same time.
Result: Unpredictable final value due
to race conditions.
34.
Incrementing a sharedcounter in a parallel loop: Using #pragma omp atomic
int counter = 0;
#pragma omp parallel for
for (int i = 0; i < 1000; i++) {
#pragma omp atomic
counter++; // Safe
}
Ensures single, indivisible update to
counter.
Best for simple operations like +=, ++,
etc.
Faster than critical for basic
assignments.
.
35.
Incrementing a sharedcounter in a parallel loop: Using #pragma omp critical
int counter = 0;
#pragma omp parallel for
for (int i = 0; i < 1000; i++) {
#pragma omp critical
{
counter++; // Safe
}
}
Protects complex or compound
operations.
Slower than atomic due to locking
overhead.
Useful when multiple shared
variables or logic are involved.
.
36.
#include<stdio.h>
#include<omp.h>
int main()
{
#pragma ompparallel
{
int tid = omp_get_thread_num();
printf("Thread %d reached phase 1n", tid);
#pragma omp barrier // All threads wait here
printf("Thread %d starting phase 2n", tid);
}
return 0;
}
It ensures that all threads in a
team reach the same point
before any can proceed
Prevents race conditions
when threads depend on
shared data modified earlier.
Ensures correct sequencing of
operations across threads.
#pragma omp barrier
synchronization directive in OpenMP
37.
Drawbacks:
Deadlock risk ifnot all threads reach the barrier.
Performance overhead if one thread lags (load imbalance).
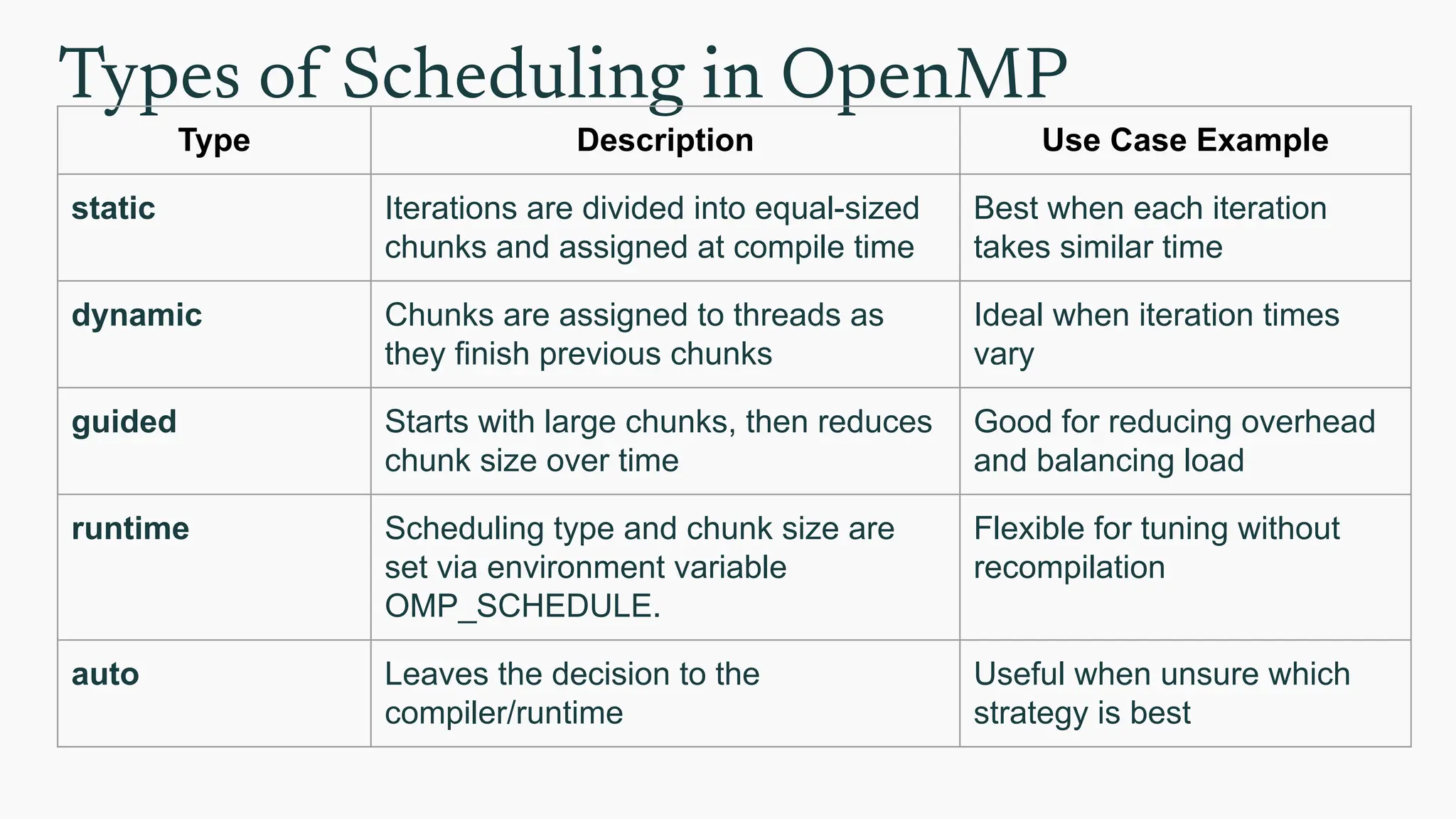
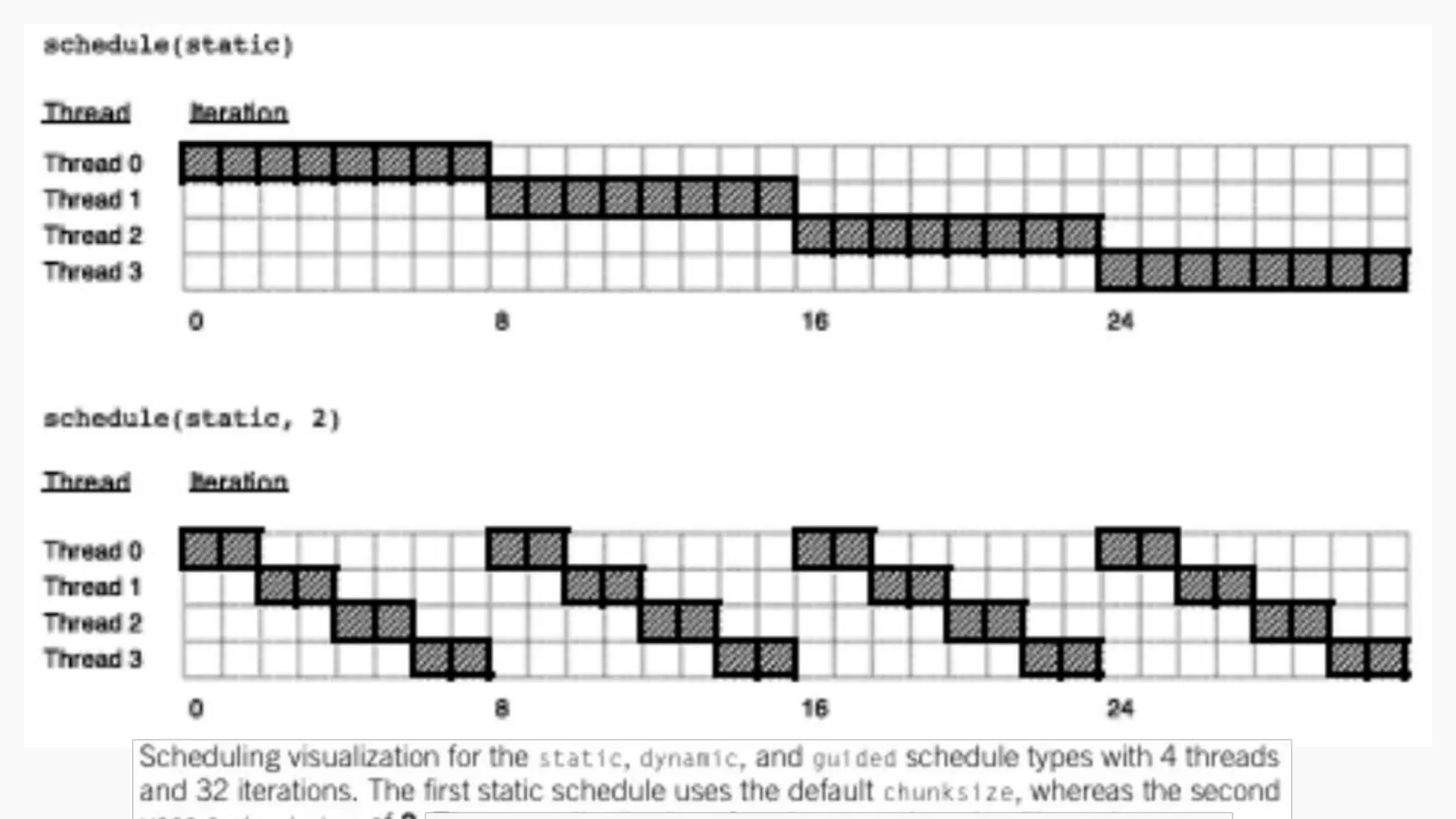
Scheduling loops
● Theschedule clause in OpenMP is used within #pragma omp for or
#pragma omp parallel for directives to control how loop iterations are
divided among threads.
● This clause is crucial for optimizing performance and ensuring efficient
load balancing.
● It determines:
○ How iterations are split into chunks
○ How those chunks are assigned to threads
● This helps minimize thread idle time and ensures better utilization of
CPU cores.
42.
Types of Schedulingin OpenMP
Type Description Use Case Example
static Iterations are divided into equal-sized
chunks and assigned at compile time
Best when each iteration
takes similar time
dynamic Chunks are assigned to threads as
they finish previous chunks
Ideal when iteration times
vary
guided Starts with large chunks, then reduces
chunk size over time
Good for reducing overhead
and balancing load
runtime Scheduling type and chunk size are
set via environment variable
OMP_SCHEDULE.
Flexible for tuning without
recompilation
auto Leaves the decision to the
compiler/runtime
Useful when unsure which
strategy is best
43.
● Only static,dynamic, and guided schedules can have a
chunksize.
● In a static schedule, the chunks of chunksize iterations are
assigned in round robin fashion to the threads.
● In a dynamic schedule, each thread is assigned chunksize
iterations, and when a thread completes its chunk, it requests
another chunk.
● In a guided schedule,the size of the chunks decreases as the
iteration proceeds.
44.
For a staticschedule, the system assigns chunks of chunksize
iterations to each thread in a round-robin fashion.
Suppose we have 12 iterations, 0,1,...,11, and three threads.
Assignment of iterations:
schedule(static , 1)
● Thread 0 : 0,3,6,9
● Thread 1 : 1,4,7,10
● Thread 2 : 2,5,8,11
schedule(static , 2)
● Thread 0 : 0,1,6,7
● Thread 1 : 2,3,8,9
● Thread 2 : 4,5,10,11
schedule(static , 4)
● Thread 0 : 0,1,2,3
● Thread 1 : 4,5,6,7
● Thread 2 : 8,9,10,11
47.
#include <stdio.h>
#include <omp.h>
intmain() {
int n = 20;
printf("Scheduling with STATICn");
#pragma omp parallel for schedule(static, 4)
for (int i = 0; i < n; i++) {
printf("STATIC: Thread %d does iteration %dn", omp_get_thread_num(), i);
}
printf("nScheduling with DYNAMICn");
#pragma omp parallel for schedule(dynamic, 4)
for (int i = 0; i < n; i++) {
printf("DYNAMIC: Thread %d does iteration %dn", omp_get_thread_num(), i);
}
return 0;
}
48.
Tasking
● OpenMP tasksare used in cases of unstructured parallelism, especially for
workloads that don’t fit neatly into loops—like recursive algorithms, dynamic
data structures, or irregular computations.
● A task is a unit of work that can be executed independently.
● Important constructs:
○ #pragma omp task: is the directive in OpenMP that lets you define a unit of work—a task.
The runtime decides when and by which thread it gets executed.
○ #pragma omp taskwait: is an OpenMP directive used to synchronize tasks, it.ensures that
child tasks complete before proceeding.
49.
The task directivecan be used to get parallel threads to execute different
sequences of instructions.
For example, if our code contains three functions, f1, f2, and f3 that are
independent of each other, then the serial code is:
f1(args1);
f2(args2);
f3(args3);
50.
The serial codecan be parallelized by using the following directives:
The parallel directive
will start three threads.
If we omitted the single
directive, each function
call would be executed
by all three threads.
The single directive
ensures that only one of
the threads calls each of
the functions.
51.
If each ofthe functions returns a value and we want to add these values, we can
put a barrier before the addition by adding a taskwait directive:
#pragma omp sectionsis a powerful OpenMP construct for task parallelism — letting
different threads execute distinct code blocks concurrently
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallel sections
{
#pragma omp section
{
printf("Task A executed by thread %dn", omp_get_thread_num());
}
#pragma omp section
{
printf("Task B executed by thread %dn", omp_get_thread_num());
}
#pragma omp section
{
printf("Task C executed by thread %dn", omp_get_thread_num());
}
}
return 0;
}
● The parallel sections
directive creates a team
of threads.
● Each section is treated
as an independent task.
● OpenMP assigns each
section to a thread — if
there are more sections
than threads, some
threads may execute
multiple sections.
● There's an implicit
barrier at the end unless
you use nowait.
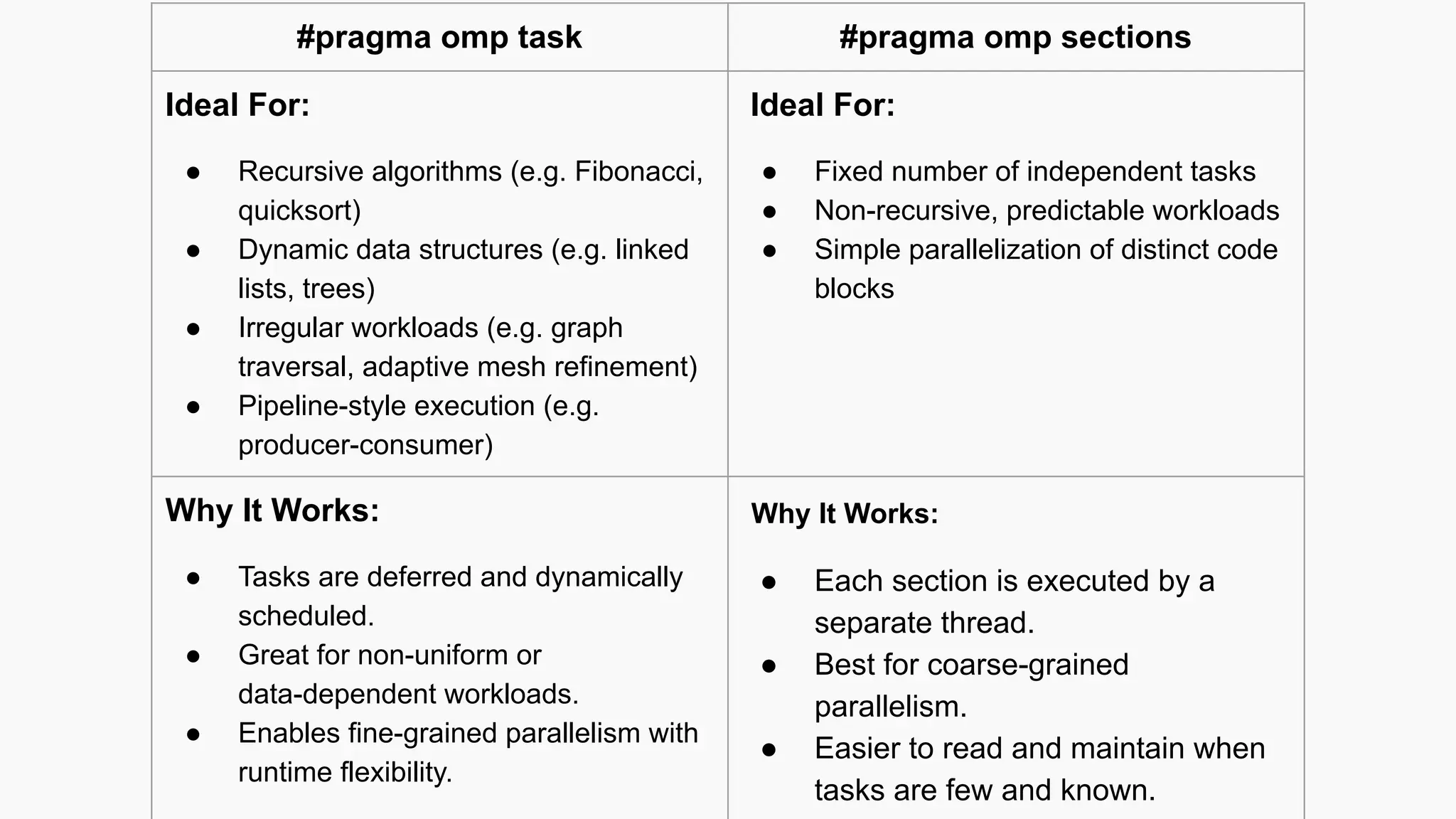
#pragma omp task#pragma omp sections
Ideal For:
● Recursive algorithms (e.g. Fibonacci,
quicksort)
● Dynamic data structures (e.g. linked
lists, trees)
● Irregular workloads (e.g. graph
traversal, adaptive mesh refinement)
● Pipeline-style execution (e.g.
producer-consumer)
Ideal For:
● Fixed number of independent tasks
● Non-recursive, predictable workloads
● Simple parallelization of distinct code
blocks
Why It Works:
● Tasks are deferred and dynamically
scheduled.
● Great for non-uniform or
data-dependent workloads.
● Enables fine-grained parallelism with
runtime flexibility.
Why It Works:
● Each section is executed by a
separate thread.
● Best for coarse-grained
parallelism.
● Easier to read and maintain when
tasks are few and known.
56.
Coarse-grained parallelism refersto dividing a program into large, independent
tasks that can be executed in parallel. Each task performs a substantial amount of
computation before needing to communicate with others.
Fine-grained parallelism divides a program into many small tasks, each
performing a minimal amount of computation before needing to communicate or
synchronize.
57.
Dynamic data structures(like linked lists, trees, graphs, etc.) are unpredictable in size and
layout, so fixed scheduling strategies can fall short.
Irregular Workload Handling: Iterating over a dynamic structure often leads to unbalanced
computation. Tasks allow you to create work units for individual nodes, branches, or
segments—each handled independently.
2. Recursive Processing: tructures like binary trees or DAGs often use recursion. With
OpenMP tasks, you can create a task for each recursive call, enabling true parallel
traversal.
58.
Producers and Consumers
Theproducer-consumer pattern in OpenMP is a bit tricky
because OpenMP is designed for data parallelism on
shared-memory systems — not for traditional thread
communication.
Producer threads might “produce” requests for data from
a server
Consumer threads might “consume” the request by
finding or generating the requested data
Challenge: Synchronize access to shared resources
without race conditions.
59.
Producers and Consumers:Queues
● The producer threads could enqueue, and the consumer
threads could dequeue them.
● The process wouldn’t be completed until the consumer
threads had given the requested data to the producer threads.
60.
Producers and Consumers:Message-passing
● implementing message-passing on a shared-memory system.
● Each thread could have a shared-message queue, and when
one thread wanted to “send a message” to another thread, it
could enqueue the message in the destination thread’s queue.
● A thread could receive a message by dequeuing the message
at the head of its message queue.
61.
Message-passing: Sending messages
Accessinga message queue to enqueue a message is a critical
section.
● to efficiently enqueue, store a pointer to the rear.
● When we enqueue a new message, we’ll need to check and
update the rear pointer.
● If two threads try to do this simultaneously, we may lose a
message that has been enqueued by one of the threads.
● The results of the two operations will conflict, and hence
enqueuing a message will form a critical section.
# pragma omp critical
Enqueue ( queue , dest , my_rank , mesg ) ;
62.
Message-passing: Receiving messages
●Only the owner of the queue (that is, the destination thread)
will dequeue from a given message queue.
● As long as we dequeue one message at a time, if there are at
least two messages in the queue, a call to Dequeue can’t
possibly conflict with any calls to Enqueue.
● keep track of the size of the queue, to avoid any
synchronization (for example, critical directives), as long as
there are at least two messages.
● size of the queue.,store two variables,-enqueued and
dequeued, then the number of messages in the queue is:
queue_size = enqueued − dequeued
● the only thread that will update dequeued is the owner of
the queue.
Message-passing: Termination detection
Thefollowing implementation will have problems:
queue_size = enqueued - dequeued;
if (queue_size == 0)
return TRUE;
Else
return FALSE;
If thread u executes this code, it’s entirely possible that some
thread (thread v) will send a message to thread u after u has
computed queue_size = 0.
After thread u computes queue_size = 0, it will terminate and the
message sent by thread v will never be received.
65.
Thus if weadd a counter done_sending, and each thread
increments this after completing its for loop, then we can
implement Done as follows:
queue_size = enqueued - dequeued;
if (queue_size == 0 && done_sending ==t hread_count)
return TRUE;
Else
return FALSE;
66.
Caches, cache coherenceand false sharing in
OpenMP
Cache memory is a small, fast storage located close to the CPU
that holds frequently accessed data and instructions. It acts as a
buffer between the CPU and main memory (RAM) to reduce access
latency.
When CPU requests data, Cache checked first.
If found → cache hit → fast access
If not → cache miss → fetch from RAM
Missed data is stored in cache for future use
67.
Cache Coherence: Ensuresall cores see the same value for
shared data.
False Sharing: Occurs when threads update different variables on
the same cache line, causing unnecessary coherence traffic and
performance loss.
68.
Since the unitof cache coherence, a cache line or cache block, is
usually larger than a single word of memory, this can have the
unfortunate side effect that two threads may be accessing different
memory locations, but when the two locations belong to the same
cache line, the cache-coherence hardware acts as if the threads
were accessing the same memory location—if one of the threads
updates its memory location, and then the other thread tries to
read its memory location, it will have to retrieve the value from main
memory.
That is, the hardware is forcing the thread to act as if it were
actually sharing the memory location. Hence, this is called false
sharing, and it can seriously degrade the performance of a
shared-memory program.
69.
Thread-safety
Another potential problemthat occurs in shared-memory
programming is thread-safety.
A block of code is thread-safe if it can be simultaneously
executed by multiple threads without causing problems.
70.
● Some Cfunctions cache data between calls by declaring variables
to be static.This can cause errors when multiple threads call the
function; since static storage is shared among the threads, one
thread can overwrite another thread’s data. Such a function is not
thread-safe, and, unfortunately, there are several such functions in
the C library.
● Sometimes, however, the library has a thread-safe variant of a
function that isn’t thread-safe.
71.
Examples of somefunctions that are not thread safe
● strtok function in string.h: tokenize lines (uses a static
internal pointer to track the current position in the string across
multiple calls.)
● the random number generator rand in stdlib.h (uses a global
static seed to generate pseudo-random numbers.Every call to
rand() updates this shared seed.If multiple threads call rand()
simultaneously, they may corrupt the seed or produce
unexpected results)
● time conversion function localtime in time.h (localtime() uses
a static struct tm to store the result.)
thread-safe version of strtok: strtok_r























![#include <omp.h>
#include <stdio.h>
int main() {
int A[10];
for (int i = 0; i < 10; i++) A[i] = i;
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10; i++) {
sum += A[i]; // Race condition!
}
printf("Sum = %dn", sum);
return 0;
}
Sum the elements of an array in parallel- without reduction clause
All threads try to update
sum simultaneously.
This causes a race
condition — unpredictable
results
.
Not thread-safe unless
you use atomic, critical, or
reduction.](https://image.slidesharecdn.com/parallelcomputingbcs702module4-251123070925-5b9ab5b8/75/Parallel-Computing-BCS702-Module-notes-of-the-vtu-college-7th-sem-4-pdf-31-2048.jpg)
![#include <omp.h>
#include <stdio.h>
int main() {
int A[10];
for (int i = 0; i < 10; i++) A[i] = i;
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 10; i++) {
sum += A[i];
}
printf("Sum = %dn", sum);
return 0;
}
Sum the elements of an array in parallel- with reduction clause
Each thread gets a private
copy of sum.
After the loop, OpenMP
automatically combines all
partial sums.
Thread-safe, no race
conditions.](https://image.slidesharecdn.com/parallelcomputingbcs702module4-251123070925-5b9ab5b8/75/Parallel-Computing-BCS702-Module-notes-of-the-vtu-college-7th-sem-4-pdf-32-2048.jpg)



































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)














